

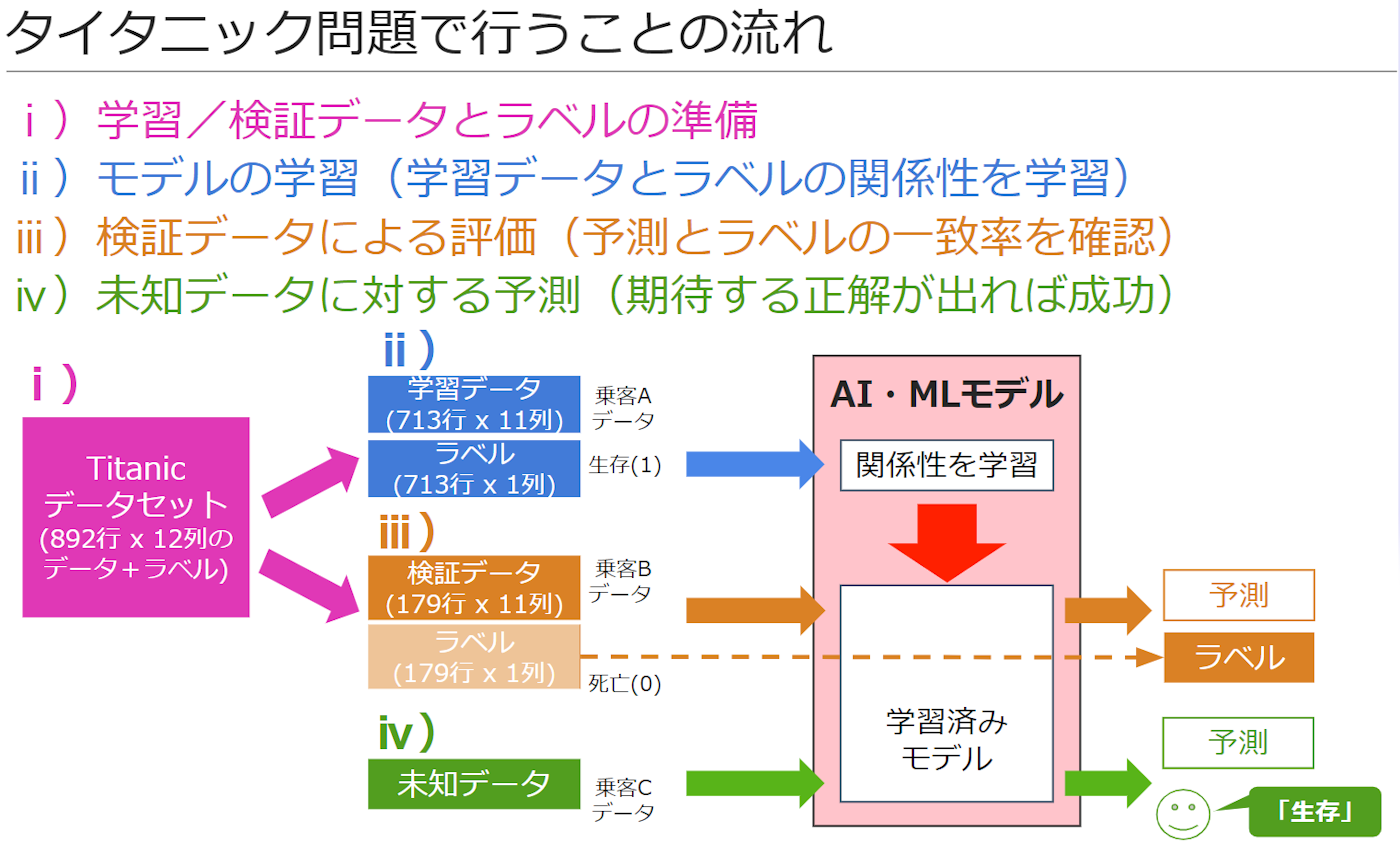
タイタニック問題
Mix.install([
{:nx, "~> 0.4"},
{:axon, "~> 0.3"},
{:exla, "~> 0.4"},
{:csv, "~> 3.0"},
{:statistics, "~> 0.6"},
{:kino_vega_lite, "~> 0.1.7"}
])概要
- Kaggleのデータで「データ前処理」の基礎を学ぶ
- タイタニック問題
資料
- Eixirで機械学習に初挑戦④:ElixirでKaggleに挑戦(前編) by piacerex
- Eixirで機械学習に初挑戦⑤:ElixirでKaggleに挑戦(後編) by piacerex
- Elixir生誕10周年祭■第3弾:Elixir/Livebook+NxでPythonっぽくAI・ML by piacerex
ⅰ)学習データの準備
ⅰ-1.生データの収集
- Download titanic data
titanic_dir = "../notebooks/piacerex/titanic"
train_data_csv_file = Path.join(titanic_dir, "train.csv")
test_data_csv_file = Path.join(titanic_dir, "test.csv")ⅰ-2.生データをLivebookにロード
# Load train data from a CSV file
load_raw_train_data = fn file_path ->
File.stream!(file_path)
|> CSV.decode!()
|> Enum.to_list()
end
train_csv_rows = load_raw_train_data.(train_data_csv_file)ⅰ-3.データ操作しやすくするためにマップ群に変換
raw_train_data_to_maps = fn [header_row | data_rows] ->
# A list of lowercase atoms
train_data_keys =
for col <- header_row do
col
|> String.downcase()
|> String.to_atom()
end
# A list of maps
for data_row <- data_rows do
train_data_keys
|> Enum.zip(data_row)
|> Enum.into(%{})
end
end
train_csv_maps = raw_train_data_to_maps.(train_csv_rows)ⅰ-4.学習のための最低限の「データ前処理」
- Ensure that data entries contain number numbers
- Ensure that data entries are relevant to labels
①空白値の確認
count_missing_values = fn datas ->
datas
|> Enum.flat_map(fn entry ->
entry
|> Map.filter(fn {_k, v} -> v == "" end)
|> Map.keys()
end)
|> Enum.frequencies()
end
count_missing_values.(train_csv_maps)②ID/ラベル/学習データを分離
separate_ids_and_labels = fn datas, id_key, label_key ->
ids = Enum.map(datas, &Map.fetch!(&1, id_key))
# * Nx.tensorでの行列化できる値は小数だが、ラベルは整数文字列なので、
# 整数の後ろに「.0」を付加し、String.to_floatすることで小数化
# * モデルに入力できるよう、「2次元行列のリスト」に変換する必要があるが、
# ラベル群は単なるリストのため、2次元行列で包むために、2重リスト[[~]]で囲んだ上で、
# Nx.tensorに渡す
# * 未知データにはラベルが無いので、ラベルが無い場合はnilを返す
labels =
if Map.has_key?(List.first(datas), label_key) do
Enum.map(
datas,
fn entry ->
Nx.tensor([
[String.to_float("#{Map.fetch!(entry, label_key)}.0")]
])
end
)
else
nil
end
maps = Enum.map(datas, &Map.drop(&1, [id_key, label_key]))
{ids, labels, maps}
end
{
train_csv_ids,
train_csv_labels,
train_csv_maps
} = separate_ids_and_labels.(train_csv_maps, :passengerid, :survived)③特徴とならない列の削除
タイタニック問題で「特徴と言えないデータ」に該当すると思われるのは以下です
-
cabin (部屋番号)
- 部屋番号は、生存率にとても高い相関性を持っているはずですが、Cabinは891件中、687件と大量のデータが欠損しているため、使い物にならないと判断し、削除
-
name(乗客名)
- 乗客名は、全員が異なり、生存率にも無関係と思われる
- 名字が同じで、チケット番号が近い or 部屋が近い等であれば、家族乗船の可能性があり、家族全員がボートに乗れるまで待ったとき生存率が低くなる、といった仮説は考えられるが、いったん削除
-
ticket(チケット番号)
- チケット番号そのものは、生存率に無関係と思われる
- 近い番号の方が、生存率の高い/低い部屋番号にまとまって配置されたという可能性は考えられるが、憶測の域を出ないので、いったん削除
drop_columns = fn datas, keys ->
for data <- datas do
Map.drop(data, keys)
end
end
train_csv_maps_dropped =
train_csv_maps
|> drop_columns.([:cabin, :name, :ticket])④欠損値の補完
補完対象
-
欠損値のうち、
cabinは列ごと削除されたので、残るageとemberkedが補完対象
補完方法
- 中央値/平均値/最頻値など、該当項目の統計値で補完
- 該当項目以外のデータ群から、該当項目の値を推測
- 欠損していること自体が特徴となる場合、欠損値をカテゴリ値として扱う
- 全項目の欠損傾向から、新たな項目を作り、欠損値は削除する
資料
complete_missing_values = fn datas, mapping ->
for {key, replacement_value} <- mapping, reduce: datas do
acc ->
for entry <- acc do
empty_string_regex = ~r/^$/
current_value = Map.fetch!(entry, key)
new_value = String.replace(current_value, empty_string_regex, replacement_value)
Map.replace!(entry, key, new_value)
end
end
end
train_csv_maps_replaced =
train_csv_maps_dropped
|> complete_missing_values.(embarked: "S", age: "30", fare: "32")⑤カテゴリ値(種別文字列)を数値に変換
- 種別を表す文字列の数値化
- 「ダミー変数」と呼ばれることもある
- こうした置換自体を「ワンホットエンコーディング」と呼ぶこともある
make_dummy_mapping = fn datas, key ->
datas
|> Enum.map(&Map.get(&1, key))
|> Enum.uniq()
|> Enum.with_index(&{&1, String.to_float("#{&2}.0")})
|> Enum.into(%{})
endmake_dummy_mapping.(train_csv_maps_replaced, :embarked)make_dummy_mapping.(train_csv_maps_replaced, :sex)make_dummy_mapping.(train_csv_maps_replaced, :foo)ポイント:検証データや未知データではカテゴリ値が網羅されていないケースへの対策として、学習データからカテゴリ値を拾えるようにするため、あらかじめカテゴリ値生成用のデータを別に受け取れるようにしておく。
default_dummy = 10.0
replace_with_dummies = fn datas, dummy_source, keys ->
for key <- keys, reduce: datas do
acc ->
dummy_mapping = make_dummy_mapping.(dummy_source, key)
if dummy_mapping do
acc
|> Enum.map(fn entry ->
current_value = entry[key]
dummy_value = dummy_mapping[current_value] || default_dummy
Map.put(entry, key, dummy_value)
end)
else
acc
end
end
end
train_csv_maps_dummied =
train_csv_maps_replaced
|> replace_with_dummies.(train_csv_maps_replaced, [:embarked, :sex, :honor])⑥整数を小数に変換
- 数値文字列から数値への変換
-
整数と小数が混在する列は、文字列から数値への変換を
String.to_integerとString.to_floatを使い分けしなければならなくて面倒なため、整数文字列を全て小数文字列に変換した上で、小数に変換
numeric_fields = [:age, :fare, :parch, :pclass, :sibsp]
replace_numeric_string_with_float = fn datas, keys ->
for key <- keys, reduce: datas do
acc ->
for entry <- acc do
case Map.fetch!(entry, key) do
current_value when is_number(current_value) ->
entry
nil ->
raise("key #{key} is nil: #{inspect(entry)}")
current_value ->
entry
|> Map.replace!(
key,
current_value
|> String.replace(~r/^(?!.*\.).*$/, "\\0\.0")
|> String.to_float()
)
end
end
end
end
train_csv_maps_numericized =
train_csv_maps_dummied
|> replace_numeric_string_with_float.(numeric_fields)⑦数値を行列に変換
- 数値をモデルに入力できるよう、「2次元行列のリスト」に変換
maps_to_tensors = fn datas ->
for data <- datas do
# This might need sorting but seems working as is
Nx.tensor([Map.values(data)])
end
end
train_csv_datas =
train_csv_maps_numericized
|> maps_to_tensors.()⑧「データ前処理」全体の関数化
- ここまでの「データ前処理」をprocessという関数で1発で完了するようにします
ⅰ-5.精度を向上させるための「データ前処理」
①年齢と料金の補完値を中央値に修正
- ここでは、比較的カンタンに実装できる中央値/平均値を取り上げる
ageのデータ分布
まず、グラフでageのデータ分布を見てみる(学習データに欠損値が存在するのでEnum.rejectで除去)
ages =
train_csv_maps
|> Enum.reject(&(&1.age == ""))
|> replace_numeric_string_with_float.([:age])
|> Enum.map(&Map.take(&1, [:ticket, :age]))VegaLite.new(width: 800, height: 400)
|> VegaLite.data_from_values(ages, only: ["ticket", "age"])
|> VegaLite.mark(:point)
|> VegaLite.encode_field(:x, "ticket", type: :nominal)
|> VegaLite.encode_field(:y, "age", type: :quantitative)Elixirで統計を取得するときに便利なライブラリ「Statistics」を使って、中央値/平均値/最頻値を取ってみる
## 中央値
ages
|> Enum.map(& &1.age)
|> Statistics.median()## 平均値
ages
|> Enum.map(& &1.age)
|> Statistics.mean()## 最頻値
ages
|> Enum.map(& &1.age)
|> Statistics.mode()fareのデータ分布
fares =
train_csv_maps
|> replace_numeric_string_with_float.([:fare])
|> Enum.map(&Map.take(&1, [:ticket, :fare]))VegaLite.new(width: 800, height: 400)
|> VegaLite.data_from_values(fares, only: ["ticket", "fare"])
|> VegaLite.mark(:point)
|> VegaLite.encode_field(:x, "ticket", type: :nominal)
|> VegaLite.encode_field(:y, "fare", type: :quantitative)fares
|> Enum.map(& &1.fare)
|> Statistics.median()fares
|> Enum.map(& &1.fare)
|> Statistics.mean()fares
|> Enum.map(& &1.fare)
|> Statistics.mode()②EDA(探索的データ分析)に基づく改善アイデア
-
モデルを作る前に、データに何らかの傾向を見出す
- データ分布の特性や偏りを発見
- 特徴の例外たる「外れ値」を除外
- スプレッドシートやExcelの利用が有効なことも多い
敬称(title of honor)を集計
-
nameフィールドから敬称を取り出し、その値をhonorフィールドに追加する
# <first name>, <honor>. <last name>
# E.g., "Braund, Mr. Owen Harris"
name_to_honor = fn name ->
name
# `<first name>, `を取り除く
|> String.replace(~r/^.*, /, "")
# `. <last name>`を取り除く
|> String.replace(~r/. .*/, "")
end
put_honor = &Map.put(&1, :honor, name_to_honor.(&1.name))
train_datas_with_honor =
load_raw_train_data.(train_data_csv_file)
|> raw_train_data_to_maps.()
|> Enum.map(put_honor)honor_counts =
train_datas_with_honor
|> Enum.map(& &1.honor)
|> Enum.frequencies()
|> Enum.map(fn {k, v} -> %{honor: k, count: v} end)VegaLite.new(width: 600, height: 200)
|> VegaLite.data_from_values(honor_counts, only: ["honor", "count"])
|> VegaLite.mark(:bar)
|> VegaLite.encode_field(:x, "honor", type: :nominal)
|> VegaLite.encode_field(:y, "count", type: :quantitative)
honorとsurvivedの相関関係を確認
survived_honor_count =
train_datas_with_honor
|> Enum.map(&Map.take(&1, [:honor, :survived]))
|> Enum.frequencies()
|> Enum.map(fn {k, v} -> %{survived_honor: "#{k.honor}-#{k.survived}", count: v} end)VegaLite.new(width: 800, height: 400)
|> VegaLite.data_from_values(survived_honor_count, only: ["survived_honor", "count"])
|> VegaLite.mark(:bar)
|> VegaLite.encode_field(:x, "survived_honor", type: :nominal)
|> VegaLite.encode_field(:y, "count", type: :quantitative)
sexとsurvivedの相関関係を確認
survived_sex_counts =
load_raw_train_data.(train_data_csv_file)
|> raw_train_data_to_maps.()
|> Enum.map(&Map.take(&1, [:sex, :survived]))
|> Enum.frequencies()
|> Enum.map(fn {k, v} -> %{survived_sex: "#{k.sex}-#{k.survived}", count: v} end)VegaLite.new(width: 600, height: 400)
|> VegaLite.data_from_values(survived_sex_counts, only: ["survived_sex", "count"])
|> VegaLite.mark(:bar)
|> VegaLite.encode_field(:x, "survived_sex", type: :nominal)
|> VegaLite.encode_field(:y, "count", type: :quantitative)ⅰ-6.「データ前処理」全体の関数化
- ここまでの「データ前処理」をprocessという関数で1発で完了するようにします
missing_value_mapping = [embarked: "S", age: "0", fare: "0"]
ignored_fields = [:cabin, :name, :ticket]
dummied_fields = [:embarked, :sex, :honor]
numeric_fields = [:age, :fare, :parch, :pclass, :sibsp]
load_datas_from_csv_file = fn file_path ->
load_raw_train_data.(file_path)
|> raw_train_data_to_maps.()
|> separate_ids_and_labels.(:passengerid, :survived)
end
put_honor = fn datas ->
for entry <- datas do
Map.put(
entry,
:honor,
# <first name>, <honor>. <last name>
# E.g., "Braund, Mr. Owen Harris"
entry.name
# `<first name>, `を取り除く
|> String.replace(~r/^.*, /, "")
# `. <last name>`を取り除く
|> String.replace(~r/. .*/, "")
)
end
end
process_datas = fn datas, dummy_source ->
datas
|> put_honor.()
|> drop_columns.(ignored_fields)
|> complete_missing_values.(missing_value_mapping)
|> replace_with_dummies.(
dummy_source |> complete_missing_values.(missing_value_mapping),
dummied_fields
)
|> replace_numeric_string_with_float.(numeric_fields)
|> maps_to_tensors.()
end
{train_csv_ids, train_csv_labels, train_csv_maps} = load_datas_from_csv_file.(train_data_csv_file)
train_datas =
process_datas.(train_csv_maps, train_csv_maps)
|> Enum.zip(train_csv_labels)ⅱ)モデルの学習
学習時のランダム性
- 学習済みモデルでの予測は、同じデータに対して常に同じ予測を返す一方、学習は毎回、異なるモデルを生成するため、予測精度に変化が出る
- 最適化関数の「Adam」のベースとなっている「SGD」がランダムにデータを取り出している
- https://kunassy.com/oprimizer/#toc5
###
model =
Axon.input("input", shape: {nil, 7})
|> Axon.dense(48, activation: :tanh)
|> Axon.dropout(rate: 0.2)
|> Axon.dense(48, activation: :tanh)
|> Axon.dense(1, activation: :sigmoid)
trained_state =
model
|> Axon.Loop.trainer(:mean_squared_error, Axon.Optimizers.adam(0.0005))
|> Axon.Loop.metric(:accuracy, "Accuracy")
|> Axon.Loop.run(train_datas, %{}, epochs: 20, compiler: EXLA)ⅲ)検証データによる評価
ⅳ)未知データによる予測
①未知データのロードと学習データの列差異の確認
- 未知データにはラベルが無い
- 未知データ中に、学習データに無いパターンが存在しているかも知れません
[train_csv_header | _] = load_raw_train_data.(train_data_csv_file)
[test_csv_header | _] = load_raw_train_data.(test_data_csv_file)
train_csv_header -- test_csv_header{test_csv_ids, _, test_csv_maps} = load_datas_from_csv_file.(test_data_csv_file)
honorのラベルを確認
####
{_, _, train_csv_maps} = load_datas_from_csv_file.(train_data_csv_file)
{_, _, test_csv_maps} = load_datas_from_csv_file.(test_data_csv_file)
honor_counts = fn csv_maps ->
csv_maps
|> put_honor.()
|> Enum.map(& &1.honor)
|> Enum.frequencies()
end
honor_counts_train = honor_counts.(train_csv_maps)
honor_counts_test = honor_counts.(test_csv_maps)
[train: honor_counts_train, test: honor_counts_test]Map.keys(honor_counts_test) -- Map.keys(honor_counts_train)②空白値の確認
- 未知データに学習データと異なる欠損値が無いかチェック
test_csv_maps
|> count_missing_values.()test_csv_maps
|> drop_columns.(ignored_fields)
|> complete_missing_values.(missing_value_mapping)
|> count_missing_values.()③未知データに対する予測の実施
{test_csv_ids, _, test_csv_maps} = load_datas_from_csv_file.(test_data_csv_file)
# 第二引数に、学習データを渡すことがポイント
# これは検証データや未知データではカテゴリ値が網羅されていないケースへの対策
processed_datas = process_datas.(test_csv_maps, train_csv_maps)
result =
processed_datas
|> Enum.map(fn data ->
Axon.predict(model, trained_state, data)
|> Nx.to_flat_list()
|> List.first()
|> round()
end)
|> then(fn predicted_labels ->
Enum.zip(test_csv_ids, predicted_labels)
end)
|> Enum.map(fn {id, predicted_label} ->
[id, "#{predicted_label}"]
end)
|> then(fn entries ->
[["PassengerId", "Survived"]] ++ entries
end)Kaggleへの提出CSV作成
csv_data =
result
|> CSV.encode()
|> Enum.to_list()
# file_name = "prediction_#{:os.system_time(:second)}.csv"
# File.write(file_name, csv_data)





